Trends in ethical concerns in the use of models
As a reflection on concerns in society
In 1984 Jim Diamond issued the song I should have known better. It is about a lost love. In the second line he explains what went wrong: To lie to one as beautiful as you
There is a lot to unpack here. Let me start with the ‘should have known’. Did he really not know at the time, or did he conveniently ignore this knowledge. He probably wanted to have the short-term benefits and ‘forget’ that there is a huge price to pay later. If it is legal to do, there is nothing wrong with it, is it? Just apologize and we are OK again, aren’t we? In the song the lady didn’t buy it.
Quite often organisations do the same. Only checking if something is technically legal to do, does not prevent scandals. The price to pay later is way higher than the original benefits. There is a business case for ethical behavior in an organisation. On a broader scale, many big problems in society, such as low self-esteem with children, over-consumption, income inequality, climate change, truth collapse, attention disorders, and the decline of democracies are caused by organisational behavior that is technically legal. Laws are always lagging behind. With AI becoming more powerful, organisations must shift their focus from the question ‘can we do this’ to ‘should we do this’.
That brings me to the second line in the song to unpack: To lie to one as beautiful as you. That did not age well. While 60 years ago that was apparently OK to say, nowadays it screams discrimination and male chauvinism. Ethics are not static in time. The same concepts, like privacy or discrimination, get a different connotation in time. And that is important to understand as an organisation because you will get judged on the connotation of these concepts as they will be in the future, not on how they are now or 10 years ago. You should have known better in the eyes of society.
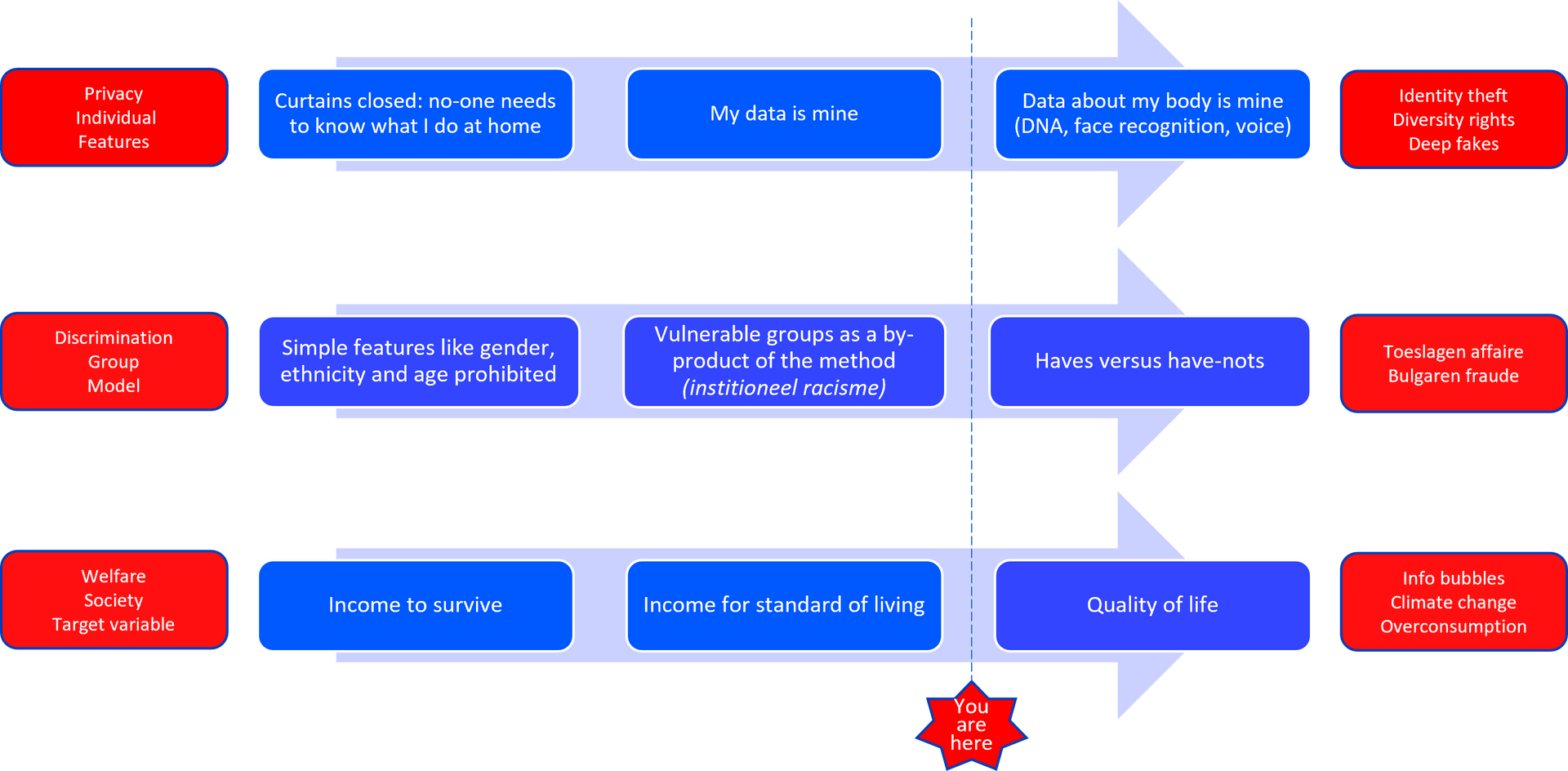
So how does this relate to using AI and data and models in general? There a basically 3 components when using AI:
- The input data: features, characteristics that go into the model
- The model itself: simple to highly complex statistics
- The target variable: the concept the model is trying to predict
The ethical dilemmas are not just in the model, but in all three components, but they differ in main concern:
- Input data: main concern is about privacy, and relevant on an individual level
- Model: main concern is about discrimination, and relevant at a group level
- Target variable: main concern is about welfare, and relevant at society level
So far so good. So just keep GDPR or AVG in mind, check for biases, and aim for the right thing and we are fine, aren’t we? No you should have known better problem in the future. Unfortunately, it is not that easy: there is a moving target. The meaning of privacy, discrimination and welfare evolve in time and it is important to understand these changes and anticipate on them.
Privacy
Let’s start with privacy, on the individual level, relating to the input features. For my parents privacy meant closed curtains. Today it is ‘my data is mine’, reflected in GDPR/AVG rules. But this will change, and hopefully not the hard way, into ‘data about my body is mine’. Today people are typically careless in sharing their pictures, voice, video, and some even their DNA.
The big you should have known better privacy issues of the (near) future are about identity theft, diversity rights and deep fakes. With GenAI getting better and better, everybody can impersonate anybody, at scale. It could be a hostile foreign regime creating fake news or an angry neighbour getting a loan in your name. And we all know this, but still, I see companies experimenting with client identification through voice recognition, and companies storing bio-metric information with the huge risk of a data breach. You should have known better.
Discrimination
Now for discrimination, on the group level, relating to the model. Also this concept is not static. Initially it meant you can’t discriminate on features like age, sex or ethnicity. These groups should be treated equally. Obviously, that is still valid, but when data scientists talk about discrimination in models it is typically about unintended side effects of a model, resulting in disadvantaging vulnerable subgroups. In all the statistical checks this is not a problem, because the groups can be relatively small. But it can result in institutionalized racism.
Organisations should be mindful that the connotation of the word "discrimination" will undergo further changes, and it is essential to anticipate these potential shifts. There already is a discussion in society about the distribution of wealth, the rich getting richer and the poor getting poorer. Same goes for the discussion about the fairness of the difference between income from labour and income from capital. In the current scandals where models discriminate the have-nots pay the price. I think organisations will get challenged in the future on whether they made the gap between the haves and the have-nots bigger or smaller. Do not go for I should have known better.
Welfare
The trend on welfare is on society level, and relates to what we are optimizing. What do we choose as the target of our models? My grandparents (and most contemporaries) worked because they needed the money to feed the family. Never mind working conditions, friendly bosses, they just needed the job. It was income to survive. After World War 2 that changed to income for standard of living. More and better products for more people. More is better; economic growth is the main target.
But the younger generation (perhaps unless extremely in the have-nots group) places more value on quality of life, including non-tangibles like clean air, friends and biodiversity. The current economic model that most organisations still pursue is about maximizing profit, not maximizing client value. Organisations still (also) sell products that society does not need at all, or do not match the actual client needs. Organisations spend lots of time and money persuading clients that they need their product, instead of fulfilling actual needs. Supporting climate change, overconsumption or putting people in information bubbles just to sell more adds is not adding to quality of life
Yardstick
My guess is that that these three aspects of Responsible AI will be the main yardstick of the future. Do not wait until something is not allowed anymore. Just singing I should have known better and saying sorry did not work for Jim Diamond, and probably will not work for your organisation either
If your organisation needs help in the next steps in responsible AI, including the implementation of the new EU AI act, please reach out to me, always happy to help.